- 首页 > 非靶向代谢组学
非靶向代谢组学
基于液质联用技术(LC-MS),无偏向性、尽可能多地检测细胞、组织、器官或体液等生物样本内所有的小分子代谢物,对实验组和对照组进行对比分析,通过统计分析筛选差异代谢物,对差异代谢物进行代谢通路分析,进而寻找代谢物与生理病理变化的相对关系。
技术优势
1. 代谢物鉴定准确度高
使用标准品数据库鉴定,提供鉴定可信度分级注释,鉴定总数2,000+
2. 超高分辨率质谱平台
使用QE系列谱仪进行检测,仪器分辨率高、质量精度高、稳定性好
3. 规范化平台严格质控
全流程标准操作程序(SOP)指导,同位素内标与QC双重质控
4. 大样本项目经验丰富
高通量自动化样本制备系统进行代谢物提取,实时监控仪器检测过程
产品应用
- 疾病诊断、发病机理及预后研究
- 微生物感染及发病机理研究
- 肠道菌群与疾病研究
- 机体发育调控研究
- 药物作用机制及靶点研究
- 天然药物研究与新药筛选
技术路线
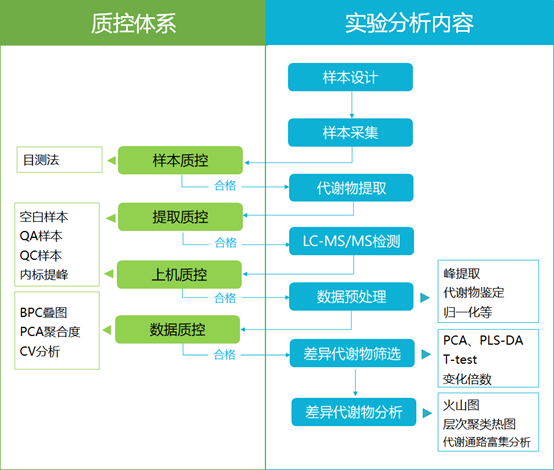
技术参数
1. 仪器平台
LC-MS/MS:液相-Waters ACQUITY UPLC,质谱-Thermo Q Exactive / Q Exactive HF/Q Exactive HF-X
2. 分析软件
Compound Discoverer(Thermo, USA),metaX (华大自主开发的代谢组学分析软件包)
3. 数据库
华大代谢组数据库(BGI MDB, BGI Metabolome Database) ,包含保留时间、一级质谱和二级质谱信息
mzCloud 在线标准品数据库,包含一级质谱和二级质谱信息,化合物数量19000+
其他数据库 HMDB、KEGG、LIPID MAPS等
项目周期
30-60个自然日
案例一:L-肉碱治疗后败血性休克1年存活患者和死亡患者之间代谢组差异[1]
研究背景:
败血性休克具有40%的致死率,L-肉碱是治疗败血症休克的候选治疗药物。患者对L-肉碱的反应可能取决于其独特的代谢特征,而这些特征在临床表型中并不明显。为更好地了解败血症患者的代谢变化与以患者为中心的预后之间的关系,对接受L-肉碱治疗的患者血清样本采用非靶向代谢组学的手段检测。
技术路线:
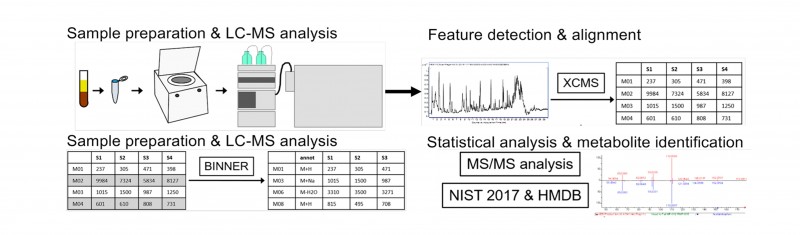 图1 研究技术路线
图1 研究技术路线
主要结论:
1. 对L-肉碱和安慰剂治疗后的患者代谢组数据进行热图分析发现L-肉碱治疗后存活和死亡患者代谢组成具有明显差异,且接受安慰剂治疗的患者具有显著异质性。
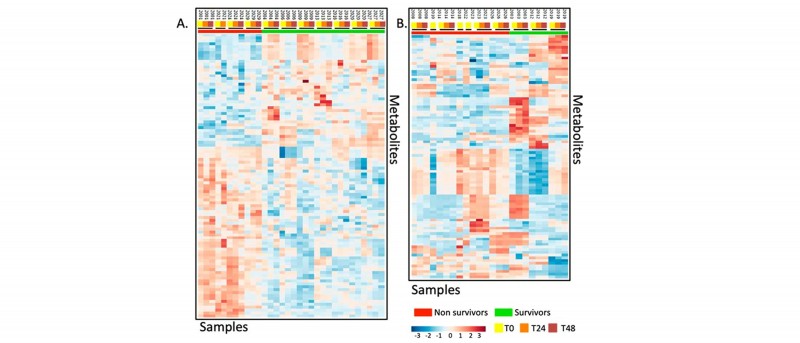
图2 不同处理组之间代谢物热图分析
2. 对接受L-肉碱治疗的患者不同时间点(T0h、T24h、T48h)取样分析,发现酰基肉碱的水平升高,但是整体代谢组并没有发生剧烈扰动。
3. 接受L-肉碱治疗后的1年存活患者和死亡患者具有显著的代谢表型差异,表明这些差异的代谢物可能是体内代谢过程紊乱的副产物;包括纤维蛋白肽A、醛赖氨酸、组胺等几种与血管炎症相关的几种代谢标记物在死亡患者中显著上调。这些代谢指标的变化可以用做评估患者预后反应差异。
案例二:代谢组学研究早期结直肠癌生物标志物[2]
研究背景:
本研究是对结直肠癌(CRC)诊断生物标志物的研究,而流行病学研究表明代谢综合征增加了患结直肠癌的风险,且癌症的早期筛查能够有效地增加患者5年生存率,代谢组学对研究系统生物学小分子生物标志物有重要意义。本研究旨在为CRC的诊断确定可靠的血清生物标志物。
研究内容:
样本选择:人血清样本
队列选择:筛选队列(360例)、验证队列(1,594例)、验证队列(900例)、预测队列(1,528例)
研究方法:非靶向代谢组、靶向代谢组
技术路线:
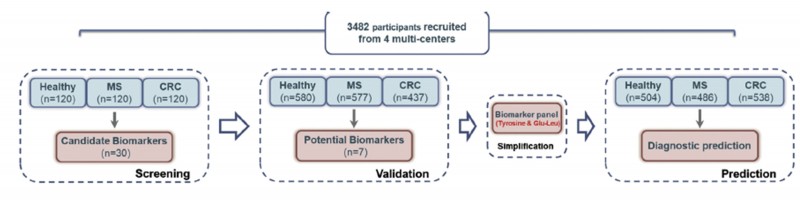
图1 技术路线图
主要发现:
1. 筛选队列:选择360血清个样本(120例健康人、120例代谢综合征患者、120例结直肠癌患者)进行非靶向代谢组学代谢物筛选,通过两两比较组分析得到30个差异表达代谢物,通过通路注释分析发现这些差异代谢物主要与苯丙氨酸代谢途径、甘油磷脂代谢途径、苯丙氨酸、酪氨酸、色氨酸合成途径相关。
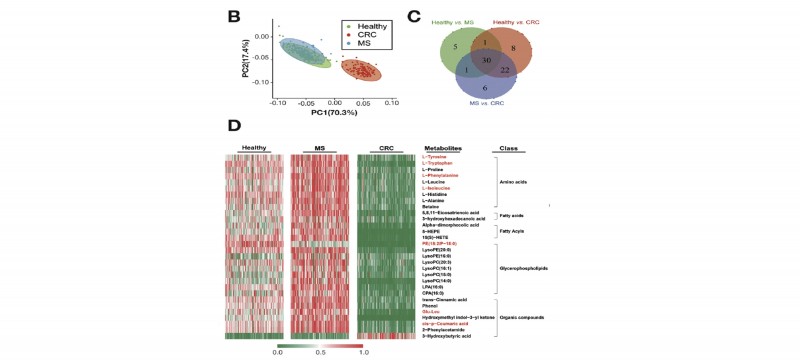
图2 差异代谢物聚类分析
2. 确认队列:采用1,594个独立队列(580例健康人、577例代谢综合征患者、437例结肠癌患者)进行验证,利用PCA和OPLS-DA分析得到7个代谢物可作为潜在的生物标志物,通过与疾病表型进行关联分析和二元逻辑回归分析确定酪氨酸、谷氨酰胺-亮氨酸作为生物标志物,能够明确的区分健康人群和结直肠癌患者。
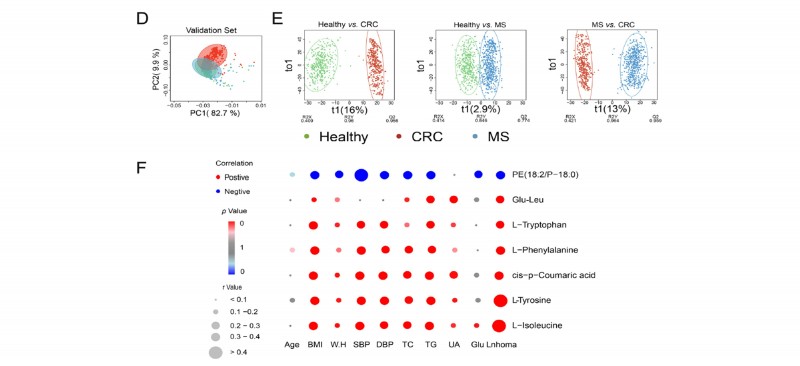
图3 确认队列中筛选7种潜在生物标志物
3. 验证队列、疾病预测队列:接着对酪氨酸、谷氨酰胺-亮氨酸这2个生物标志物通过900个验证队列,采用受试者特征曲线分析进一步评估了这2个生物标志物的准确性;最后挑选1528个人群作为预测队列,分别评估标志物的诊断能力的可靠性。
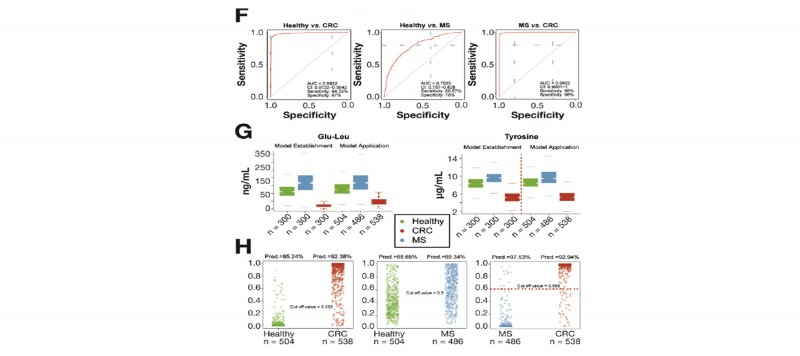
图4 验证队列对2种生物标志物验证
参考文献
[1] Evans, Charles R., et al. "Untargeted metabolomics differentiates L-carnitine treated Septic shock 1-year survivors and nonsurvivors." Journal of proteome research 18.5 (2019): 2004-2011.
[2] Li, Jiankang, et al. "Tyrosine and Glutamine-Leucine Are Metabolic Markers of Early-Stage Colorectal Cancers." Gastroenterology 157.1 (2019): 257-259.
1. 数据预处理及质控分析
使用Compound Discoverer软件进行LC-MS/MS数据处理,主要包括峰提取、峰对齐和代谢物鉴定等一系列分析。Compound Discoverer导出的数据通过metaX进行数据预处理、质控分析和后续分析。数据质控的内容包括,QC样本的BPC重叠图、所有样本的PCA分析、各组的CV分析。
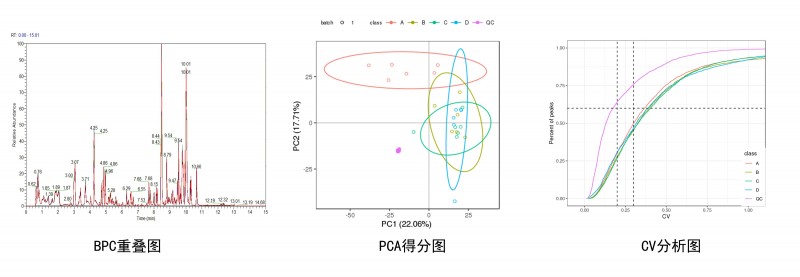
图1 数据质控分析
2. 代谢物的检测和鉴定情况
(1)代谢物检测数和鉴定数统计
对数据预处理后的代谢物检测数量和鉴定数量统计如下表。
表1 代谢物检测数和鉴定数统计表
|
离子模式 |
代谢物检测数 |
代谢物鉴定数 |
|
pos |
5,182 |
2,359 |
|
neg |
2,749 |
1,291 |
pos—正离子模式,neg—负离子模式。
(2)代谢物的分类注释和功能注释分析

图2 代谢物的分类注释和功能注释统计图
3. 差异代谢物的筛选
通过PCA分析观察了解两组样本的差异情况。采用多变量分析PLS-DA模型前两个主成分的VIP值,结合单变量分析差异变化倍数(Fold Change, FC)和T检验(Student's t-test)的q-value值来筛选差异表达的代谢物。筛选条件: 1)VIP ≥ 1;2) Fold-Change ≥1.2 或者 ≤ 0.8333;3) q-value < 0.05,同时满足这三个条件,即为差异代谢物。
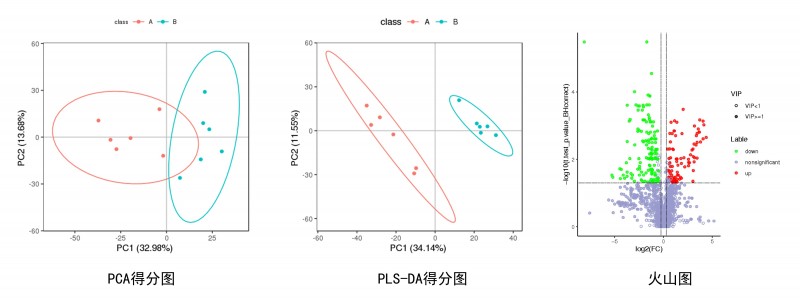
图3 差异代谢物的筛选
4. 差异代谢物分析
包括差异代谢物的聚类热图分析和差异代谢物的代谢通路富集分析。
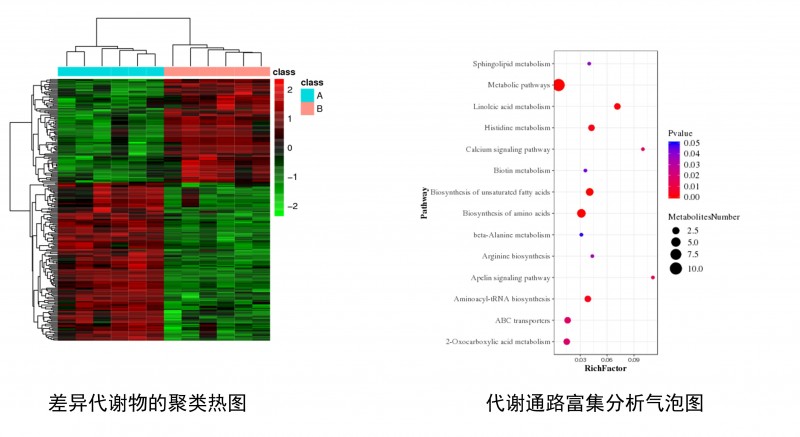
图4 差异代谢物的分析
1. 重复数要求
每组样本的生物学重复次数要求如下,重复次数越多越好。
表1 生物学重复次数要求
|
样本类型 |
重复次数要求 |
|
植物、微生物、细胞样本 |
≥ 6个 |
|
动物样本 |
≥
10个 |
|
临床样本 |
≥ 30个 |
2. 送样量要求
表2 送样量要求
|
样本类型 |
建议送样量/例 |
|
血清、血浆 |
≥ 250 µL |
|
尿液 |
≥ 500 µL |
|
动物及临床组织 |
≥ 200 mg |
|
粪便、肠道内容物 |
≥ 200 mg |
|
细胞 |
≥ 107 个 |
|
微生物 |
≥ 107个或≥100 mg |
|
培养液、发酵液 |
≥ 1 mL |
Q1:“非靶向代谢组学”的代谢物鉴定数量是多少?
A1:代谢物鉴定数一般可以达到2,000+,鉴定结果的准确度和数量在行业内属于领先水平。代谢物鉴定数的多少也与样本本身的含有的代谢物数量多少有关,不同物种、不同组织器官样本代谢物种类含量不同;如果样本中的代谢物数量本身就比较少,那么检测和鉴定到的代谢物数量也可能会少一些,以具体项目的检测鉴定情况为准。
Q2:同一代谢物在不同处理组是可以相互比较的,那么同一个个体,鉴定到的不同代谢物之间离子强度是否也可以进行相对定量的比较?或者需要一个内参?
A2:不同代谢物一般不可进行相对定量比较。由于不同的代谢物响应不同,它们之间往往是不可比的。比如,代谢物A与B在样本中的浓度相同,但代谢物A的响应率为代谢物B的100倍,那么质谱检测的代谢物A的响应比B高,但并不代表A的浓度比B高。由于一个代谢物的响应率一般是不变的,因此一个代谢物在不同样本中的响应是与其在样本中的浓度成正相关的。不同样本中相同代谢物是可比的。